
机器学习基本概念
智能时代的到来
谈到比较火的概念,那么人工智能,深度学习以及区块链等都是最近比较火的关键字。
现如今,我们正处于信息时代之中,各种各样的数据正通过无穷无尽的渠道不断的涌现:智能手机,
智能手表,浏览器,汽车,IOT,共享单车,智能家电等等。所有这些数据汇集在了各个公司的数据仓库之中,
供数据科学家对其进行整理挖掘,并产生各种各样的结果,有时候,网站甚至比你更懂你自己。
随着计算能力的提升,尤其是现如今的GPGPU(General-Purpose GPU,图形处理器的通用计算) 的飞速发展,拉开了机器学习迅猛发展的序幕。
大数据以及飞速发展的机器智能,将人类社会进一步推向了智能时代。
数据挖掘,人工智能,机器学习,深度学习等关系
那么现在经常提到的数据挖掘,人工智能,机器学习以及非常火热的深度学习之间到底有什么关系呢?
我们先来看一个大而全的图,这个图是关于数据科学家可能会用到的技能或者知识等相关领域的一些定义以及关系, 包含有数学以及统计学,计算机科学以及人工智能等。
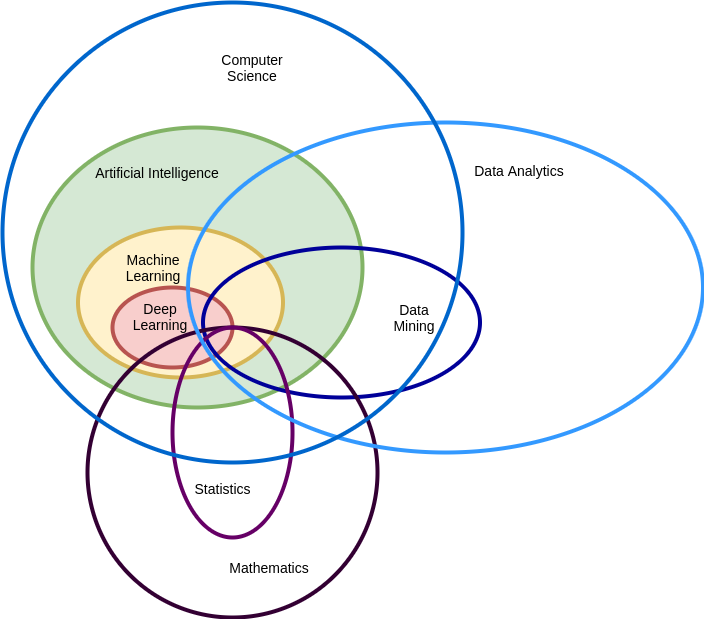
从这个图,我们可以看出来,数据挖掘属于大数据分析的一部分范畴,计算机科学的发展提升了数据挖掘的可能性以及精确性,通俗点讲就是能出结果。
人工智能是属于计算机科学的范畴的,机器学习是人工智能领域中的一部分,而火热的深度学习则仅仅是机器学习的一部分。
同时,人工智能与数据挖掘又相辅相承,人工智能做为数据挖掘的工具,而数据挖掘又可以改善数据从而提高人工智能的能力。
机器学习历史
机器学习或者人工智能甚至深度学习并不是最近几年才出现的新事物,相反他们已经出现了几十年了,
甚至人工智能这个概念比计算机出现的还要早。
参考下图,我列举了一些AI历史上的大事,自从1842年,公认的第一位程序媛Ada Lovelace伯爵夫人,第一位主张计算机不只是可以用来计算数学的人,
也发表了第一段分析机(机械式通用计算机)用的演算法,之后Alan Turing于1950年提出了著名的判断机器是否可以思考图灵测验,这一切都奠基了人工智能。
直到1956年在Dartmouth举办了第一届人工智能大会,至此Artificial Intelligence一词正式诞生。
之后的感知机模型,作为早期的只有一层的神经网络诞生,而直到异或问题的提出(感知机无法处理简单的异或计算),AI发展经历了一段黄金时期。
自从1969年异或问题提出后,人工智能进入了第一段寒冬期。
之后,1986年,多层感知机以及反向传播算法提出,解决了异或问题后,人工智能终于迎来了又一次的春天。 然而由于反向传播以及多层神经网络需要非常大的计算量,受限于当时计算机的能力,无法进行很好的应用。 1995年,Vapnik提出了SVM算法,且一度发展成为近几十年以来表现最好以及最成功的机器学习算法, 而连接主义的多层感知机则又遭遇了更深的一段寒冬期。
直到2010年前后,随着计算能力的提高,多层感知机以一个新名词深度学习开始重新崭露头角,
并在2012年的ImageNet比赛中,一举领先第二名的SVM接近10个百分点的准确率。至此深度学习重新拉开了一个新的序幕,
并在2017年AlphaGo击败了围棋世界冠军,深度学习一词登上机器学习的顶峰,并进入了普通大众的视野。
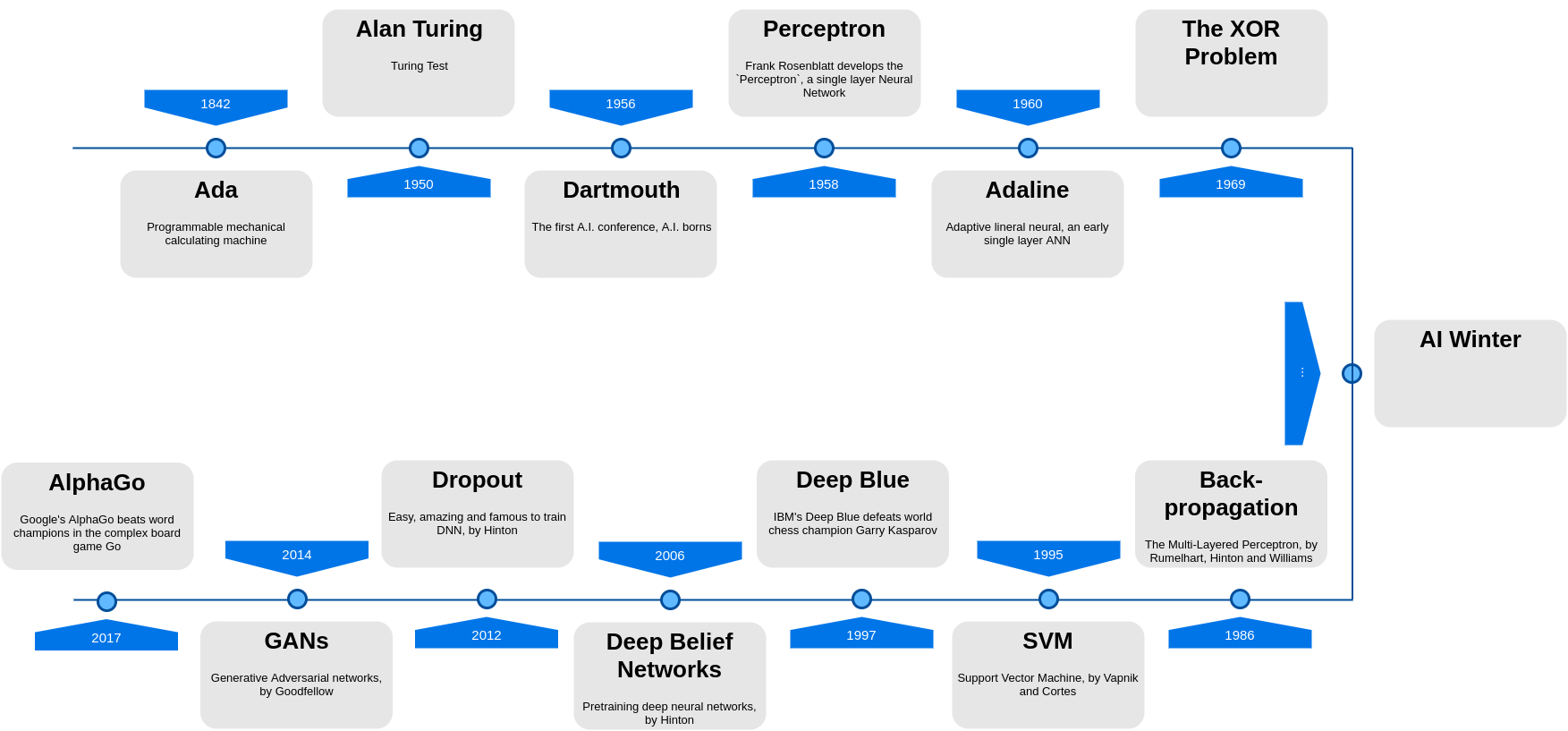
详细的人工智能历史可参考:WikiPedia 人工智能史
机器学习要解决什么问题
机器学习也是有各种算法,也是需要通过编程来解决问题的,那么为什么需要机器学习,机器学习是为了解决什么问题呢?
让我们先看看传统的做法
传统编程以及传统算法
传统的方法,我们是由人来总结经验,然后进行数学建模,最后编写计算机程序,教给计算机一套死的方法来处理某个问题。
举个例子,我们来做一下数字的辨识,对于印刷体,这个处理起来就比较简单了, 一种方法是,提供不同字体的图片,让计算机记下来,然后拿一张作为输入的印刷体图片,与已经记录好的不同字体的不同数字进行一一比较就好了。 对于死记硬背以及重复执行来说,这是计算机最擅长的两个方面。 另一种方法就是由人工提取这些印刷体的特征,比如0是上下左右都对称的,8也是上下左右都对称的,但是0中间没有像素,8则中间有像素等等规则, 然后将这些规则一一写成程序,输入计算机中,由计算机来按照程序执行比较。虽然稍微麻烦一些,但是依旧可行。
但是如果我们现在要做的不是辨识印刷体数字,而是手写的数字呢?这下有些麻烦了,我们当然可以收集几十几百万张图片,但是总有我们收集不到的手写体, 一旦输入的是我们之前没有收集到的手写体数字,那么计算机在进行图像对比的时候就非常可能出错。 如果由人工提取特征呢?似乎之前提取的那些特征依然可行,但是真正执行起来的时候,有可能就不那么好使了。 手写的数字是千奇百怪的,而且书写的时候也是有着各种角度的,这样要总结一套行之有效的特征,恐怕是一件非常困难的事情了。
机器学习的方法
机器学习是基于数据的,由人类针对某个数据集设计出一组模型簇,并教给计算机如何在这组模型簇找出最好的那一个模型,
鉴别模型好坏的依据也是基于该数据集的,这个基于数据集寻找最佳模型的过程,也就是学习的过程,也叫对机器的训练。
有点类似于我们在学校上课的时候,老师教给了我们若干种解题的方法,但是针对某些题用什么解题方法最好呢?判断的标准则是解题的答案正确与否。
那么我们就可以通过不断的做题,渐渐的摸索出对于某些题目来说,用某种解题的思路一定可以得到正确的答案,那么我们也就学习到了如何解这种题。
回到我们之前要识别数字的那个例子,如何让机器学习出识别数字呢?我们首先通过观察数字,我们认为应该能通过某些特征, 比如墨水占的比例,像素点分布,像素点对称情况等等特征,应该是可以分辨出数字的。于是我们就根据这些特征, 设计出了一堆使用这些特征来分辨数字的模型,这堆模型大体都差不多,区别在于不同的特征的侧重有些不同,也就是模型中的参数有区别。 然后,我们还设计出了一个判断模型好坏的方法(Error Function),也就是看某个模型分辨数字的准确度有多高,显而易见100%最好,0%最差。 并且,我们还设计了一个根据这个准确度,来更新我们模型参数的方法(Learning Algorithms), 也就是看看当前模型错的有多离谱,然后通过这个方法来挑选出下一个模型(更改一下参数)。 直到我们选出最好的那个模型为止。
什么时候需要机器学习
由此可见,机器学习是机器通过对数据进行一系列的计算过程,得到性能提升,来帮助人类完成不那么好完成的任务的。
那么当符合以下个条件的话,就适合应用机器学习:
- 存在一种
模式可以被总结并学得,否则机器无从学起 - 无法通过
编程的方式来解决问题,否则直接写程序就可以了 - 存在
数据可以用来学习,否则巧妇难为无米之炊
机器学习的任务
在进行机器学习的时候,目前主要是为了完成以下三大任务:
回归
回归(Regression),是一种对数值型连续随机变量进行预测和建模的监督学习算法。使用案例一般包括房价预测、股票走势或测试成绩等连续变化的案例。
回归任务的特点是标注的数据集具有数值型的目标变量。也就是说,每一个观察样本都有一个数值型的标注真值(Ground Truth)以监督算法。
分类
分类(Classification),是一种对离散型随机变量建模或预测的监督学习算法。使用案例包括邮件过滤、金融欺诈和预测雇员异动等输出为类别的任务。
许多回归算法都有与其相对应的分类算法,分类算法通常适用于预测一个类别(或类别的概率)而不是连续的数值。
聚类
聚类(Clustering),是一种无监督学习任务,该算法基于数据的内部结构寻找观察样本的自然族群(即集群)。使用案例包括细分客户、新闻聚类、文章推荐等。
机器学习的分类
监督学习
监督学习(Supervised Learning),监督学习是指训练的数据集中,针对每一笔数据,都有与之相对应的标签。 也就是说,在训练的过程中我们是知道每个样本所对应的结果的。就好比学习的过程有人判断对错,仿佛被监督了一样,而不是漫无目的的学习。 因此,监督学习也就是:在学习的过程有真值标注作为参照物来指导模型中参数调整的过程。
无监督学习
无监督学习(Unsupervised Learning),无监督学习是针对监督学习来说的,无监督学习过程中,训练数据集没有真值标注, 故而在学习过程中没有一个参照答案,无法对其所学结果判断对错。所以,无监督学习一般都用作聚类分析。
半监督学习
半监督学习(Semi-Supervised Learning),由于机器学习严重依赖于数据,而很大一部分有价值的则是由监督学习产生的,但是数据的好坏多少则严重制约监督学习的结果。 而且,现如今的数据获取很容易,但是数据的标注确要难很多,尤其是在数据量很大的情况下,标注数据则会耗费相当多的人力财力,有些情况下甚至是不可能实现的。 而半监督学习则因此而生,首先对数据进行非监督的学习,让数据聚为N类,此时再对这N类数据分别统一进行标注,这样每笔数据都有了标注了, 接下来就可以应用监督学习了。因为数据的标注不是直接进行标注,但是又不是没有标注,而这个标注又基于先自学了分类, 所以这个过程介于有监督与无监督之间,故称为半监督学习。
其实人类从小时候起,经历的学习过程大多数都为半监督学习。比如我们认识树的过程,父母只告诉了我们其中几棵是树,而没有告诉我们每一棵所见的都是树, 剩下的那些树的标记其实是由我们自动对长得比较像的先分了类,然后根据之前认识的那几棵树对其余的进行了标注。
强化学习
强化学习(Reinforcement Learning),强化学习就是要学习模型从环境到行为映射的学习,以使奖励信号最大化。 强化学习虽然也有参照物来调节参数,但是不同于监督学习,强化学习中由环境提供的奖励信号是对产生动作的好坏作一种评价,而不是告诉强化学习系统如何去产生正确的动作。 由于外部环境提供的信息很少,强化学习系统必须靠自身的经历进行学习。通过这种方式,强化学习系统在不断的尝试中,不断评价的环境中获得知识,改进行动方案以适应环境。
比如人类的各种反映动作,都是经由强化学习产生的。比如对于冷热,每个人的感受是不一样的,所以一个杯子是否烫手,别人是无法告诉我们的,只有自己感知。 当感觉烫手的时候,会产生一个疼的信号告诉大脑,这个事情不太好,从而进一步纠正我们拿起一个有着开水的杯子。
机器学习端到端过程
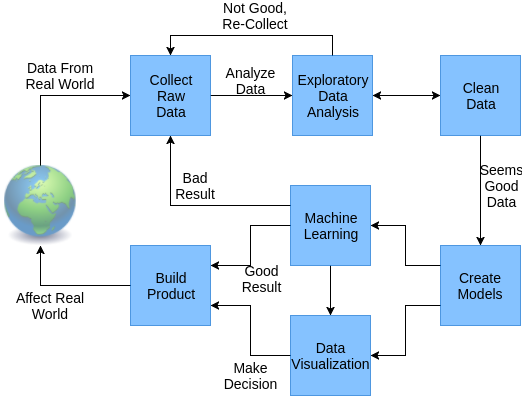
下图为对数据进行处理的一个过程,也可以理解为机器学习的一个端到端的过程。
首先,我们从真实世界收集到数据,然后我们对数据进行观察,除了统计各种数据比例之外,
也可以通过非监督学习对数据进行聚类或者降维后观察。很多时候,我们收集到的数据不是那么完美的,
有可能有缺失也可能有没用的数据,于是我们需要对数据在观察后进行清洗,观察以及清洗会交替进行多次,
直到数据看起来可用,如果数据不可用,那么要重新取数据继续之前的处理。得到可用的数据之后,
我们就可以根据观察得出的经验以及猜想来进行建模,建模后可以进行监督学习来做分类,
也可以做数据的可视化,可视化的过程中也可以应用非监督学习。在学习到模型后,可能需要产品的不同,
为了使模型可以落地使用,需要针对产品调整并实现所学到的模型。最终,我们的产品又会影响我们的世界,来产生新的数据。
机器学习未来
目前,机器学习的应用场景有很多,看起来很高科技的自动驾驶,增强现实,还是就隐藏在你我身边的购物推荐,一键磨皮等功能,
都是有着机器学习的身影在其中的。随着以后数据的不断增多,计算能力的不断增长,机器学习还可以绽放出更美丽的花朵来。
目前,机器学习也存在一定的问题,比如学术界所设计出来的机器学习模型越来越复杂,那么精简模型, 并让其能跑在小型设备上且有着比较好的准确度应该也是一个需要研究的方向; 另外,机器学习可以办到的事情很多,防止机器学习武器化应该也是一个方向,毕竟核能可以发电也可以制造原子弹,对机器学习也有着同样的担忧。
虽然目前有着一些唱衰机器学习的声音,但是这也无法阻挡机器学习对人类社会进步所做的贡献,以及机器学习的进一步发展进步。